Flex Insights Data Model Caveats
Public beta
Flex Insights (also known as Historical Reporting) is currently available as a public beta release and the information contained in the Flex Insights documentation is subject to change. This means that some features are not yet implemented and others may be changed before the product is declared as generally available. Public beta products are not covered by a Twilio SLA.
Any reference to "Historical Reporting", "Flex Insights API", "Flex Insights Historical Reporting", or "Flex Insights Historical Reporting API" in the Flex Insights documentation refers to Flex Insights.
The Flex Insights Data Model was designed for ease of use and maximum query performance. There are a few things to be aware of when working with measures and attributes.
Activity Time and Talk Time are attributed to the period in which they started.
This may cause anomalies when segmenting these measures by 15-minute, 30-minute or hourly intervals, specifically over-reporting and under-reporting Activity Time in the individual time intervals. Although daily reporting may also be affected, it is less common as agents usually do not spend time overnight in other activities than Offline.
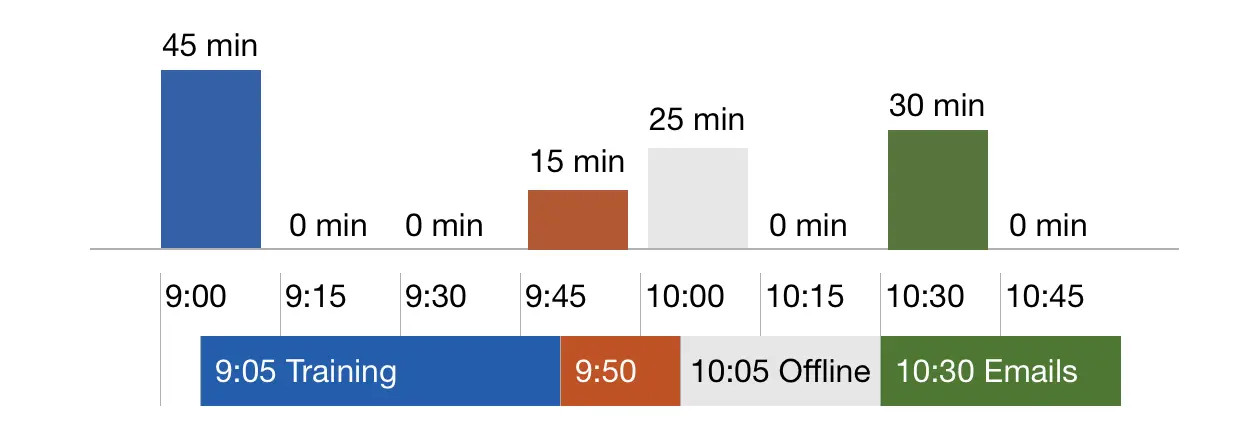
The chart below shows how the activity time is attributed to time intervals within a day.
Notice that the activity is reported in the time interval when it started. Also, note that the time intervals following the activity may have zero activity time or activity time may be lower if the beginning of the activity falls within the previous interval.
For accurate intraday reporting on Activity Time, Talk Time and Wrap Up Time use workload reporting.
The Agents dataset and Supervisors dataset may contain people you do not actually consider agents or supervisors.
- Everybody who ever handled a conversation is present in the Agents dataset.
- Everybody who ever assessed a conversation is present in the Supervisors dataset.
This means that one person can be in both the Agents and Supervisors datasets. For example, when agents rate their own conversations they will be in both datasets.
When reporting by teams, make sure you pick the right team to segment or filter the data.
As agents can move between teams over time, reporting by their current team may not be what you require.
- Handling Team - The agent's team when they handled a given conversation. This is usually the right team to use for reporting as it keeps data related to a team even after the agent moves to another team. It also prevents agents from bringing historical data from their previous teams, thus influencing measures for their current team.
- Agent Team - The current agent's team.
In most cases, Segments represent an actual conversation between customers and agents. However, we use non-conversation segments (Queue, Agent Status, Missed Conversation, Rejected Conversation) to enable more side-by-side data reporting.
Non-conversation segments should not influence your measures reporting as they have empty values in all conversation-related measures. However, sometimes when you see non-conversation segments, you may wish to filter them out explicitly.
Queue-type segments are present in every conversation but, in order to avoid double-counting, you may want to exclude them.
A measure like the following may include segments that are not related to any conversation:
SELECT COUNT (Segment)
The below measure will consist of only the segments that are related to an actual conversation:
SELECT COUNT (Segment) WHERE Kind = Conversation
Non-conversation segments have many empty measures and attributes. This means that filtering by other attributes will normally filter out non-conversation segments. Aggregation functions also filter out empty values. All the measures below will exclude non-conversation segments:
1SELECT COUNT (Segment) WHERE Abandoned = No2SELECT COUNT (Segment) WHERE Wrap Up > 03SELECT AVG (Talk Time)
In the case of internal conversations, the calling Agent is represented in the Customers dataset.
Agents in the Customers dataset have attribute Type equal to Agent. You can filter out Agents from the Customers dataset with the following condition:
SELECT COUNT (Customer) WHERE Type <> Agent